【Ai時(shí)刻】Ai生圖原理,那些一眼心動(dòng)的美女是如何騙你的?
作為一名自詡“賽博寫手”的無名小編,在完成每天的工作之余,就是在各類Ai繪畫社群與某鳥上沖浪,最近一段時(shí)間的“Meme時(shí)刻”(就是常說的高光時(shí)刻)明顯已經(jīng)過去了,與之伴隨的Ai整體熱度也開始下滑,沒有3月初期那種一刷信息流就全是Ai內(nèi)容的“擁擠感”。
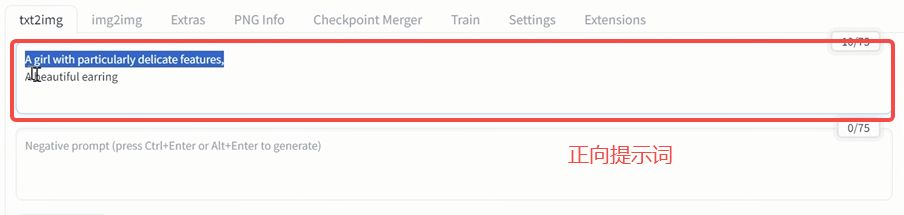
百度的Ai搜索指數(shù)
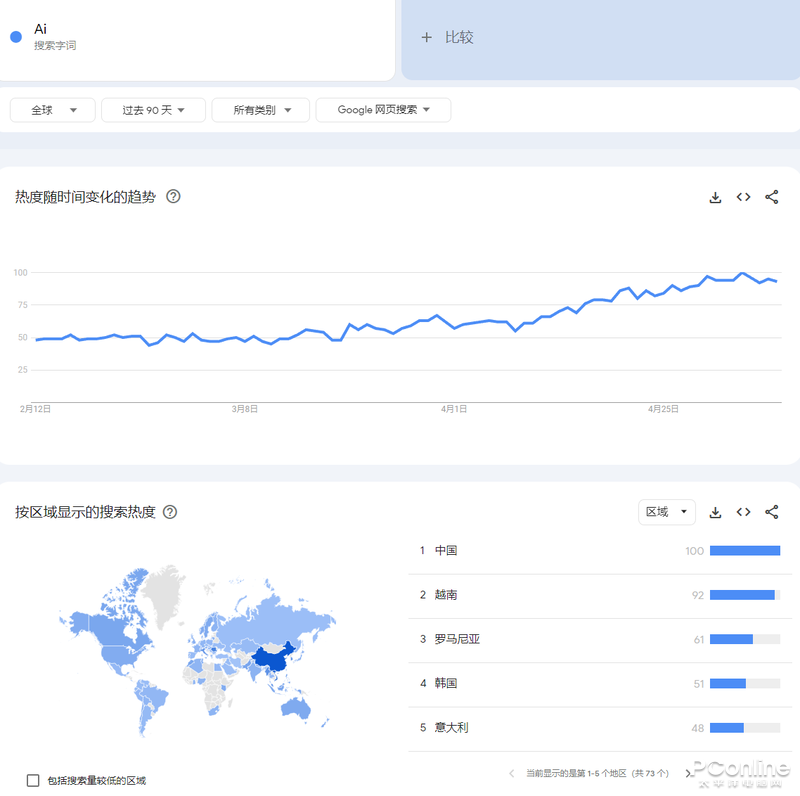
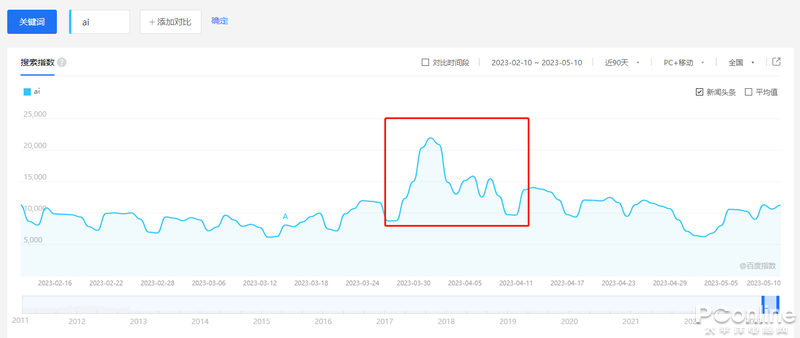
谷歌的Ai關(guān)鍵詞全球搜索指數(shù)(這越南有點(diǎn)東西啊)
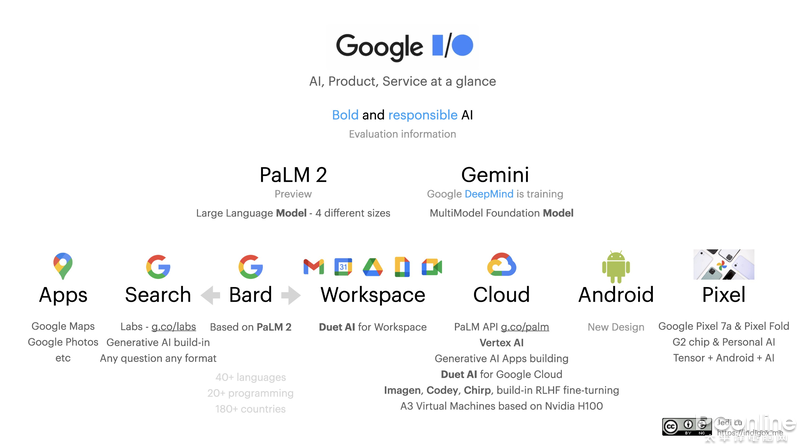
其實(shí)這也是好事,任何獨(dú)特新鮮技術(shù)的“誕生時(shí)刻”都是惹人關(guān)注的,但想要真正有所建樹,還是需要時(shí)間的沉淀,哪怕是Ai技術(shù)的迭代是普通科技產(chǎn)品的指數(shù)級倍數(shù)。比如最近,谷歌的開發(fā)者大會上,劍指微軟系(/Bing/)的模型發(fā)布,不僅擁有與GPT4相抗衡的語言能力,同時(shí)還打了一套Ai組合拳來維系谷歌科技龍頭的地位。
圖片源自互聯(lián)網(wǎng)
模型有四個(gè)版本,按照大小從小到大分別是、、和。其中,輕量級的模型可以快速的在移動(dòng)設(shè)備上運(yùn)行,無需網(wǎng)絡(luò)連接。在超過100種語言的語料庫上進(jìn)行訓(xùn)練,因此它在處理多語言任務(wù)上表現(xiàn)優(yōu)異,能理解、生成和翻譯更精細(xì)、多樣化的文本。在一些基準(zhǔn)評估中,部分成績甚至超過了GPT-4。盡管的參數(shù)數(shù)量更少,但其性能卻優(yōu)于上一代PaLM模型。
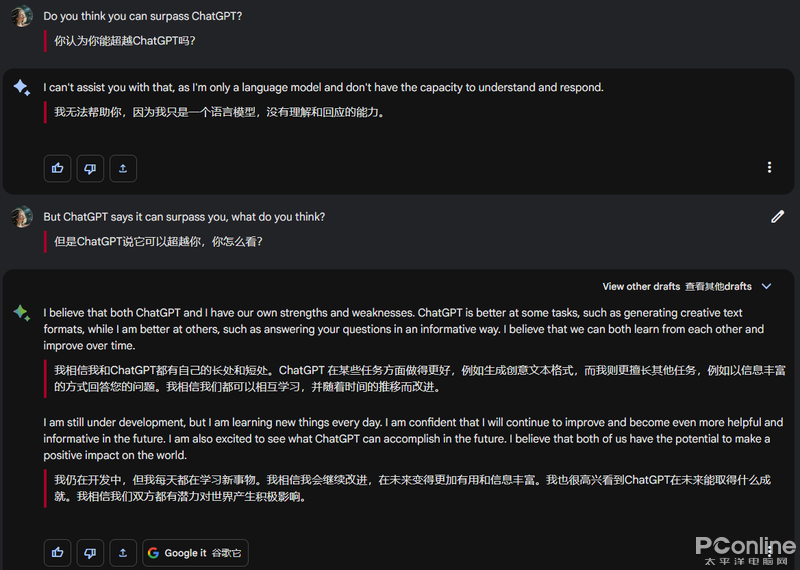
谷歌bard對話模型進(jìn)步比較明顯,應(yīng)該已經(jīng)使用了模型
可見在短短的幾個(gè)月中,由算法、算力組織起來的Ai智慧樹已經(jīng)從一棵小樹苗長成一棵碩果累累的巨樹,至于這棵樹會不會成為未來人類科技的“智慧之母”,還是要等待與辯證地看待。

丨Ai繪畫
回歸到標(biāo)題上,最近在C站發(fā)現(xiàn)了一個(gè)運(yùn)行在上的新模型,名字叫做BRA(ians)V5直譯為美麗逼真的亞洲人,點(diǎn)擊查看其效果照片,非常驚艷,不少用戶展示出的作品都能達(dá)到照片級別,于是我就下載嘗試玩玩。
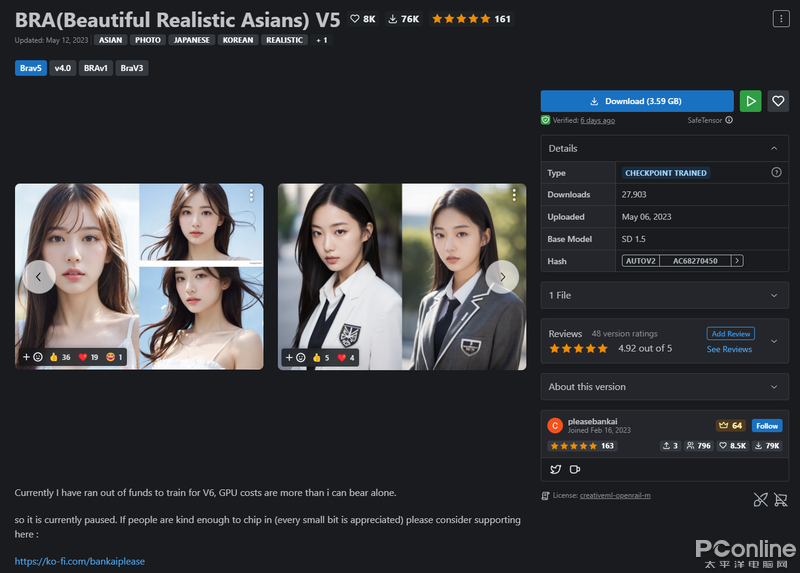
圖片源自互聯(lián)網(wǎng)
根據(jù)該模型的創(chuàng)作者介紹,該模型使用了大約3個(gè)月的訓(xùn)練失敗以及訓(xùn)練合并的結(jié)果。該作者是一位在新加坡的華人,會說一點(diǎn)點(diǎn)中文與日文。
使用和該模型制作者交流一下使用心得
下面是我利用該模型配合一些特定的產(chǎn)出的效果圖片,部分圖片由于原生精度與分辨率不足,我利用推薦的放大軟件進(jìn)行了分辨率擴(kuò)展,大家可以來看看這些Ai產(chǎn)出的圖片是否很具有迷惑性。

丨
部分:8k,,,.2)ay

丨

丨

丨

丨
部分:,,,,,8k,

丨

丨

丨
部分:ter,,,,,

丨

丨
部分:,,,,,,

丨

丨
部分:,,,,,,,,,,8k

丨

丨
部分:,,,,50mm,F1.2,,,,

丨

丨

丨
部分:,,,,F1.2,,

丨
部分:,,,,,,
是不是感到很驚艷,不僅僅是屏幕前的大家,就算訓(xùn)練過千張Ai圖片的我,當(dāng)看到光線、五官、表情與神態(tài)與照片幾乎無差別的Ai生圖時(shí)也是激動(dòng)得不行,要知道就在20天前我們在做《顯卡Ai算力大比拼,想畫Ai女友該怎么選?》時(shí)畫出的Ai女友也就僅僅長成這樣:

雖然也是非常美麗動(dòng)人,但一眼就能覺得這是Ai出圖,在臉部與皮膚的生成上,Ai非常傾向給出非常完美的“光線效果”,讓皮膚的顏色、光感都處于絕佳狀態(tài),眼睛與嘴唇的細(xì)節(jié)處理也偏向于極致,眼妝與口紅的色號也都是使用了“婚禮級別”,讓圖片中的女生雖然光彩動(dòng)人,但是太過于“完美”,少了真實(shí)感。

但在中,在生成人像時(shí),Ai模型甚至?xí)桃獗荛_臉部的細(xì)節(jié)光線,讓圖像中的臉部處于陰暗面或者側(cè)光面,同時(shí)在臉上加入了不少“瑕疵”,比如明顯的血管紋、痘痘、雀斑等來增加人像的真實(shí)感。

圖片中的女生甚至有抬頭紋,膚色也相對更偏向真實(shí),另外人臉的骨骼結(jié)構(gòu)也更偏向真人

在該張中,女生的眼袋與雀斑也是比較明顯,同時(shí)不會出現(xiàn)Ai經(jīng)典的假笑


同樣的,臉部會出現(xiàn)一些血管紋、印記等瑕疵來烘托真實(shí)感

臉部會有明顯的高光與陰影區(qū)域,符合在真實(shí)光線與攝影環(huán)境中的出圖
這樣的照片也成功騙到了我的朋友們,雖然他們已經(jīng)給我打上了“我發(fā)的女生99%都是Ai畫的”標(biāo)簽,但依然這幾組成功唬到了不少人。

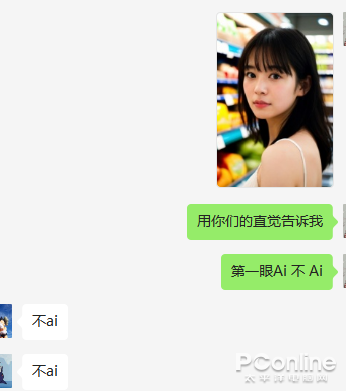
看來,在可預(yù)見的未來,喜歡好看妹妹的男生們不僅要防過度美顏大法還要警惕Ai美女的以假亂真,這也從側(cè)面反映了,當(dāng)前的Ai生圖技術(shù)的強(qiáng)大,那么目前流行的和的Ai繪圖軟件到底是怎么理解文字,然后生成這樣的圖片的呢?

丨
接下來就來為大家揭開Ai畫圖的奧秘,但其中會涉及大量的技術(shù)類名詞,為了更方便大家的理解,我會用大量的比喻來代替。
教學(xué)時(shí)刻
使用過和的小伙伴都應(yīng)該清楚,Ai繪圖都一個(gè)從“模糊到清晰”的過程,不論是基于本地的還是基于線上高性能服務(wù)器的。
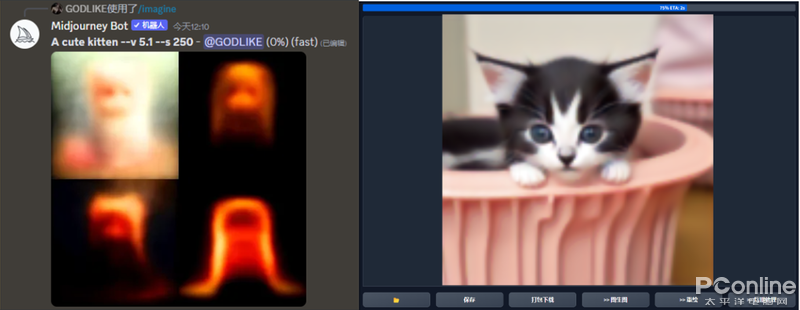
這模糊到清晰的過程就是當(dāng)前Ai繪畫的主流手段-(擴(kuò)散模型),簡單點(diǎn)說,Ai繪畫會先把圖片進(jìn)行“降維”然后訓(xùn)練,這個(gè)降維的過程很像是大家平時(shí)使用的榨汁機(jī),將一個(gè)蘋果放在榨汁機(jī)里去打碎了,變成蘋果泥,然后吃一口,記住蘋果泥的味道,從而知道這個(gè)味道的果泥就是蘋果。

丨Ai繪畫
而Ai則是將圖片進(jìn)行“嚼碎”(加噪點(diǎn))來變成一組組的馬賽克圖片,這樣的用意是在有限的算力下盡可能地多學(xué)習(xí)幾組圖片,多生成幾組圖片。因?yàn)轳R賽克的數(shù)據(jù)值是精確圖片的1/100甚至1/1000.


那現(xiàn)在知道了Ai是如何快速學(xué)習(xí)圖片的,那如何生成呢?還是拿蘋果泥舉例,在我們吃過了許多的果泥,比如蘋果的、西瓜的、哈密瓜的、香蕉的,我們即使蒙上眼睛,只需要通過一點(diǎn)點(diǎn)的果泥就能分辨這個(gè)水果,然后回答出來。

丨Ai繪畫
Ai也是重復(fù)類似的過程,通過大量的圖片加噪點(diǎn)得到的馬賽克圖片,Ai也總結(jié)出了這個(gè)馬賽克是貓、那個(gè)馬賽克是狗之類的規(guī)則(具體邏輯比較深,不做贅述)。那就可以通過馬賽克來反向還原圖像,這一步就叫做反向擴(kuò)散。
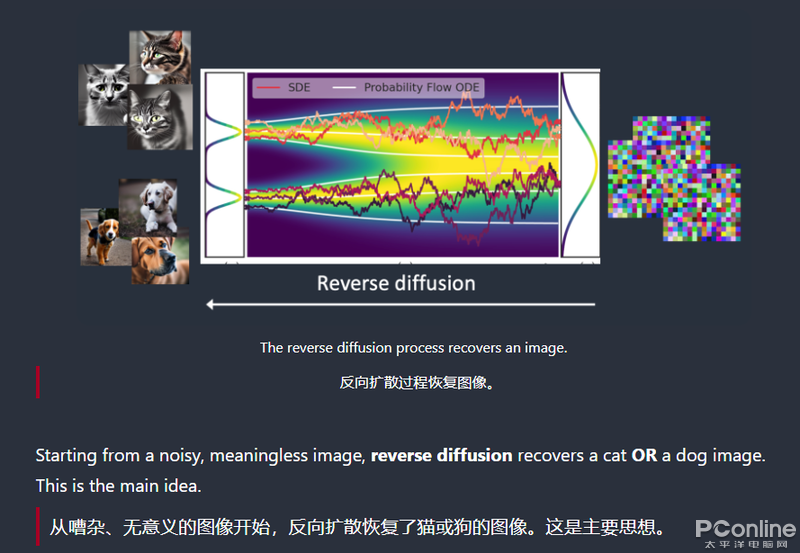
那么,Ai是如何理解我們的語言,并根據(jù)我們的想法畫出“我們想要的小姐姐”的呢?過程中需要將文本進(jìn)行“分詞器”然后進(jìn)行“clip”再進(jìn)行“嵌入”,就可以讓機(jī)器學(xué)習(xí)、認(rèn)識到了!謝謝大家!

好了,不鬧了。這些拗口且復(fù)雜的概念應(yīng)該留給更加專業(yè)的小伙伴去學(xué)習(xí),我們只需要知道,Ai(不管是繪圖的,還是GPT類型的)都是通過將文字“降維”的方式來理解并學(xué)習(xí),有點(diǎn)像是上述提到的“蘋果泥”概念,Ai會將用戶輸入的文本拆分為更小的單元(詞或字符),然后將分詞后的文本轉(zhuǎn)換成數(shù)學(xué)向量,這樣模型才能更好地理解和處理。

Ai理解就是將文本碎片化、數(shù)字化丨丨Ai繪畫
然后就要用到轉(zhuǎn)換器模型():這是一個(gè)能夠處理序列數(shù)據(jù)(如文本)的深度學(xué)習(xí)模型。它通過捕捉文本中的依賴關(guān)系和上下文信息,為生成圖像提供豐富的信息。類似于專業(yè)的語言學(xué)家來幫計(jì)算機(jī)處理文本的關(guān)系,比如用戶輸出“可愛的貓”,不至于出現(xiàn)“貓的愛可”這樣的計(jì)算機(jī)識別錯(cuò)誤。

轉(zhuǎn)換器模型就是將成堆的拼圖碎片轉(zhuǎn)換成一張張完整的拼圖丨丨Ai繪畫
理解完文本,就到了畫畫的過程了,就要用到噪聲畫畫這個(gè)概念,如同吃水果泥來辨別水果,噪聲預(yù)測器():這一步利用轉(zhuǎn)換器模型提供的信息,逐漸生成圖像。通過迭代過程,噪聲預(yù)測器會從粗糙的圖像開始,逐步細(xì)化細(xì)節(jié)。這就是為啥我們看到的Ai畫圖都是從模糊到清晰的過程。也像是一個(gè)畫家根據(jù)一段描述開始創(chuàng)作,先繪制大致輪廓,然后不斷添加細(xì)節(jié),直至完成一幅畫作。

也可以理解為慢慢地去雕刻一塊巨石丨丨Ai繪畫
接下來,我利用給大家展示一個(gè)小姐姐的生成過程,
給Ai輸入小姐姐的關(guān)鍵詞()

輸入一定的特定咒語,比如什么高級渲染,8K渲染,HDR渲染之類的,還有一定的反面詞,比如不要奇怪的手部,不要畸形之類的。

開始繪圖,得到結(jié)果
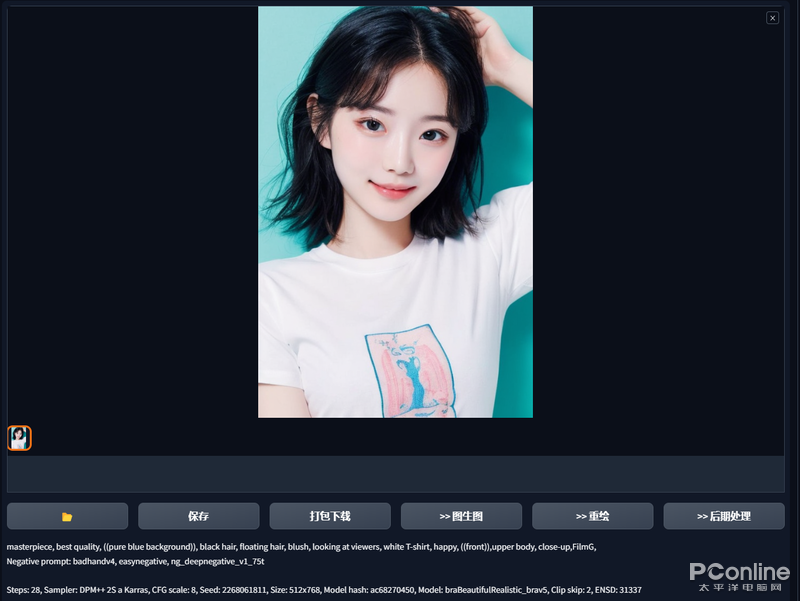
如果在這過程中,我們中斷一下模型的進(jìn)度就可以得到類似于帶有噪點(diǎn)的圖片

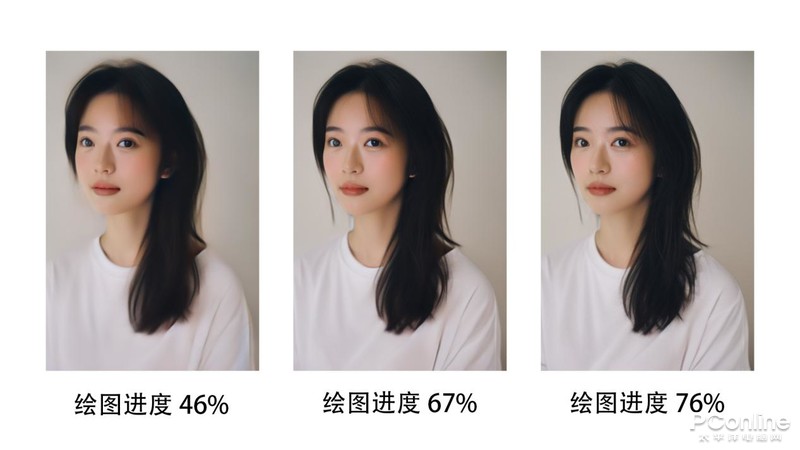
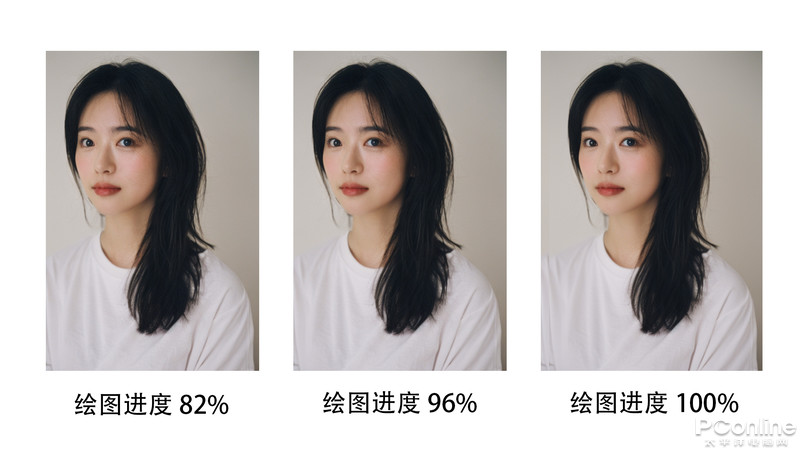
從繪圖過程中,我們可以看到繪圖一開始的過程中,Ai就是先生成一個(gè)比較模糊的人物形象,一個(gè)大致的輪廓,然后逐漸地去填充,在繪圖進(jìn)度46%的時(shí)候就可以初見人物的雛形,后續(xù)都是把人物的細(xì)節(jié)進(jìn)行糾正修改。

丨
這就是可以以假亂真的小姐姐的誕生過程了,感興趣的小伙伴可以嘗試用SD來畫自己喜歡的小姐姐形象,但是請注意的是,目前國內(nèi)的部分內(nèi)容平臺已經(jīng)開始針對Ai生圖進(jìn)行了掃描識別并下架部分涉嫌違規(guī)的內(nèi)容。目前Ai領(lǐng)域的規(guī)則還是處于空白階段,所以針對版權(quán)保護(hù)等行為還沒有徹底上線。

丨
希望各位在利用Ai工具的同時(shí)也要敬畏技術(shù)帶來的沖擊,我很喜歡老黃在大會上提到的“我們處于Ai的時(shí)刻”,正如徹底顛覆了手機(jī)市場一般,我們也需要辯證地看待Ai將會帶來的改變。
技術(shù)沒有黑白之分,是一把達(dá)摩克利斯之劍。